Коэффициент детерминации
Материал из MachineLearning.
(Новая: В статистике '''коэффициентом детерминации''', <tex>R^2</tex>, называется величина, показывающа...) |
(→Ссылки) |
||
| (3 промежуточные версии не показаны) | |||
| Строка 1: | Строка 1: | ||
| - | + | '''Коэффициент детерминации''' ('''<tex>R^2</tex>''' - ''R-квадрат'') — это доля [[дисперсия случайной величины|дисперсии]] зависимой переменной, объясняемая рассматриваемой моделью. Более точно — это единица минус доля необъяснённой дисперсии (дисперсии случайной ошибки модели, или условной по признакам дисперсии зависимой переменной) в дисперсии зависимой переменной. В случае линейной зависимости <tex>R^2</tex> является квадратом так называемого [[Множественная корреляция|множественного коэффициента корреляции]] между зависимой переменной и объясняющими переменными. В частности, для модели линейной регрессии с одним признаком <tex>x</tex> коэффициент детерминации равен квадрату обычного коэффициента корреляции между <tex>y</tex> и <tex>x</tex>. | |
| - | + | =Определение и формула= | |
| - | + | Истинный коэффициент детерминации модели зависимости случайной величины <tex>y</tex> от признаков <tex>x</tex> определяется следующим образом: | |
| - | + | : <tex>R^2 =1-\frac {V(y|x)}{V(y)}=1-\frac {\sigma^2}{\sigma^2_y},</tex> | |
| - | <tex> | + | где <tex>V(y|x)=\sigma^2</tex> — условная (по признакам <tex>x</tex>) дисперсия зависимой переменной (дисперсия случайной ошибки модели). |
| - | <tex> | + | В данном определении используются истинные параметры, характеризующие распределение случайных величин. Если использовать выборочную оценку значений соответствующих дисперсий, то получим формулу для выборочного коэффициента детерминации (который обычно и подразумевается под коэффициентом детерминации): |
| + | : <tex>R^2 =1-\frac {\hat{\sigma}^2}{\hat{\sigma}^2_y}=1-\frac {RSS/n}{TSS/n}=1-\frac {RSS} {TSS},</tex> | ||
| + | где | ||
| + | :<tex>RSS=\sum^n_{t=1}e^2_t=\sum^n_{t=1} (y_t-\hat y_t)^2</tex> — сумма квадратов регрессионных остатков, | ||
| + | :<tex>TSS=\sum^n_{t=1} (y_t-\bar{y})^2=n \hat \sigma^2_y</tex> — общая дисперсия, | ||
| + | :<tex>y_t,\hat y_t</tex> — соответственно, фактические и расчетные значения объясняемой переменной, | ||
| + | :<tex>\bar{y}=\frac{1}{n}\sum_{i=1}^n y_i </tex> — выборочное вреднее. | ||
| - | <tex> | + | В случае [[линейная регрессия|линейной регрессии]] ''с константой'' <tex>TSS=RSS+ESS</tex>, где <tex>ESS=\sum^n_{t=1} (\hat y_t-\bar{y})^2</tex> — объяснённая сумма квадратов, поэтому получаем более простое определение в этом случае. ''Коэффициент детерминации — это доля объяснённой дисперсии в общей'': |
| + | :<tex>R^2=\frac {ESS} {TSS}</tex>. | ||
| - | + | Необходимо подчеркнуть, что эта формула справедлива только для модели с константой, в общем случае необходимо использовать предыдущую формулу. | |
| - | <tex> | + | =Интерпретация= |
| + | # Коэффициент детерминации для модели с константой принимает значения от 0 до 1. Чем ближе значение коэффициента к 1, тем сильнее зависимость. При оценке регрессионных моделей это интерпретируется как соответствие модели данным. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50% (в этом случае коэффициент множественной корреляции превышает по модулю 70%). Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими (коэффициент корреляции превышает 90%). Равенство коэффициента детерминации единице означает, что объясняемая переменная в точности описывается рассматриваемой моделью. | ||
| + | # При отсутствии статистической связи между объясняемой переменной и признаками статистика <tex>nR^2</tex> для [[линейная регрессия|линейной регрессии]] имеет асимптотическое распределение <tex>\chi^2(k-1)</tex>, где <tex>k-1</tex> — число признаков в модели. В случае линейной регрессии с независимыми одинаково распределёнными нормальными случайными ошибками статистика <tex>F=\frac {R^2/(k-1)}{(1-R^2)/(n-k)}</tex> имеет точное (для выборок любого объёма) [[распределение Фишера]] <tex>F(k-1,n-k)</tex>. Информация о распределении этих величин позволяет проверить статистическую значимость регрессионной модели исходя из значения коэффициента детерминации. Фактически в этих тестах проверяется гипотеза о равенстве истинного коэффициента детерминации нулю. | ||
| - | + | = Недостатки <tex>R^2</tex> и альтернативные показатели= | |
| - | + | Основная проблема применения (выборочного) <tex>R^2</tex> заключается в том, что его значение увеличивается (''не'' уменьшается) от добавления в модель новых переменных, даже если эти переменные никакого отношения к объясняемой переменной не имеют. Поэтому сравнение моделей с разным количеством признаков с помощью коэффициента детерминации, вообще говоря, некорректно. Для этих целей можно использовать альтернативные показатели. | |
| - | <tex>R^2</tex> | + | == Скорректированный (adjusted) <tex>R^2</tex> == |
| + | Для того, чтобы была возможность сравнивать модели с разным числом признаков так, чтобы число регрессоров (признаков) не влияло на статистику <tex>R^2</tex> обычно используется ''скорректированный коэффициент детерминации'', в котором используются несмещённые оценки дисперсий: | ||
| + | :<tex>R_{adj}^2 =1-\frac {s^2}{s^2_y}=1-\frac {RSS/(n-k)}{TSS/(n-1)}=1-(1- R^2) {(n-1) \over (n-k)}\leq R^2,</tex> | ||
| + | |||
| + | который даёт штраф за дополнительно включённые признаки, где <tex>n</tex> — количество наблюдений, а <tex>k</tex> — количество параметров. | ||
| + | |||
| + | Данный показатель всегда меньше единицы, но теоретически может быть и меньше нуля (только при очень маленьком значении обычного коэффициента детерминации и большом количестве признаков), поэтому интерпретировать его как долю объясняемой дисперсии уже нельзя. Тем не менее, применение показателя в сравнении вполне обоснованно. | ||
| + | |||
| + | Для моделей с одинаковой зависимой переменной и одинаковым объемом выборки сравнение моделей с помощью скорректированного коэффициента детерминации эквивалентно их сравнению с помощью остаточной дисперсии <tex>s^2=RSS/(n-k)</tex> или стандартной ошибки модели <tex>s</tex>. | ||
| + | |||
| + | == Обобщённый (extended) <tex>R^2</tex>== | ||
| + | В случае отсутствия в линейной множественной МНК регрессии константы свойства коэффициента детерминации могут нарушаться для конкретной [[Случайный эксперимент|реализации]]. Поэтому модели регрессии со свободным членом и без него нельзя сравнивать по критерию <tex>R^2</tex>. Эта проблема решается с помощью построения обобщённого коэффициента детерминации <tex>R_{ext}^2</tex>, который совпадает с исходным для случая МНК регрессии со свободным членом. Суть этого метода заключается рассмотрении проекции единичного вектора на плоскость объясняющих переменных. | ||
| + | |||
| + | Для случая регрессии без свободного члена: | ||
| + | :<tex>R_{ext}^2 = 1- {Y'*(I-P(X))*Y \over Y'*(I-\pi(X))*Y},</tex> | ||
| + | где <tex>X</tex> — матрица <tex>n\times k</tex> значений признаков, <tex>P(X) = X*(X'*X)^{-1}*X'</tex> — проектор на плоскость <tex>X</tex>, <tex>\pi(X) = {P(X)*i_n*i_n'*P(X) \over i_n'*P(X)*i_n}</tex>, <tex>i_n</tex> — единичный вектор <tex>n\times 1</tex>. | ||
| + | |||
| + | При некоторой модификации <tex>R_{ext}^2</tex> также подходит для сравнения между собой регрессионных моделей, построенных с помощью: МНК, обобщённого метода наименьших квадратов (ОМНК), условного метода наименьших квадратов (УМНК), обобщённо-условного метода наименьших квадратов (ОУМНК). | ||
== Ссылки == | == Ссылки == | ||
* [http://www.forecastingprinciples.com/rulesforcheaters.html Rules for Cheaters: How to Get a High R squared] | * [http://www.forecastingprinciples.com/rulesforcheaters.html Rules for Cheaters: How to Get a High R squared] | ||
* [http://en.wikipedia.org/wiki/Coefficient_of_determination Wikipedia] | * [http://en.wikipedia.org/wiki/Coefficient_of_determination Wikipedia] | ||
| - | + | * [http://www.datasciencecentral.com/profiles/blogs/beginners-guide-to-regression-analysis-and-plot-interpretations?utm_content=buffer0ebf7&utm_medium=social&utm_source=twitter.com&utm_campaign=buffer Emmanuelle Rieuf: Beginners Guide to Regression Analysis and Plot Interpretations, December 7, 2016.] | |
| - | [[Категория: | + | [[Категория: Регрессионный анализ]] |
Текущая версия
Коэффициент детерминации ( - R-квадрат) — это доля дисперсии зависимой переменной, объясняемая рассматриваемой моделью. Более точно — это единица минус доля необъяснённой дисперсии (дисперсии случайной ошибки модели, или условной по признакам дисперсии зависимой переменной) в дисперсии зависимой переменной. В случае линейной зависимости
является квадратом так называемого множественного коэффициента корреляции между зависимой переменной и объясняющими переменными. В частности, для модели линейной регрессии с одним признаком
коэффициент детерминации равен квадрату обычного коэффициента корреляции между
и
.
Содержание |
Определение и формула
Истинный коэффициент детерминации модели зависимости случайной величины от признаков
определяется следующим образом:
где — условная (по признакам
) дисперсия зависимой переменной (дисперсия случайной ошибки модели).
В данном определении используются истинные параметры, характеризующие распределение случайных величин. Если использовать выборочную оценку значений соответствующих дисперсий, то получим формулу для выборочного коэффициента детерминации (который обычно и подразумевается под коэффициентом детерминации):
где
— сумма квадратов регрессионных остатков,
— общая дисперсия,
— соответственно, фактические и расчетные значения объясняемой переменной,
— выборочное вреднее.
В случае линейной регрессии с константой , где
— объяснённая сумма квадратов, поэтому получаем более простое определение в этом случае. Коэффициент детерминации — это доля объяснённой дисперсии в общей:
.
Необходимо подчеркнуть, что эта формула справедлива только для модели с константой, в общем случае необходимо использовать предыдущую формулу.
Интерпретация
- Коэффициент детерминации для модели с константой принимает значения от 0 до 1. Чем ближе значение коэффициента к 1, тем сильнее зависимость. При оценке регрессионных моделей это интерпретируется как соответствие модели данным. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50% (в этом случае коэффициент множественной корреляции превышает по модулю 70%). Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими (коэффициент корреляции превышает 90%). Равенство коэффициента детерминации единице означает, что объясняемая переменная в точности описывается рассматриваемой моделью.
- При отсутствии статистической связи между объясняемой переменной и признаками статистика
для линейной регрессии имеет асимптотическое распределение
, где
— число признаков в модели. В случае линейной регрессии с независимыми одинаково распределёнными нормальными случайными ошибками статистика
имеет точное (для выборок любого объёма) распределение Фишера
. Информация о распределении этих величин позволяет проверить статистическую значимость регрессионной модели исходя из значения коэффициента детерминации. Фактически в этих тестах проверяется гипотеза о равенстве истинного коэффициента детерминации нулю.
Недостатки 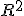 и альтернативные показатели
и альтернативные показатели
Основная проблема применения (выборочного) заключается в том, что его значение увеличивается (не уменьшается) от добавления в модель новых переменных, даже если эти переменные никакого отношения к объясняемой переменной не имеют. Поэтому сравнение моделей с разным количеством признаков с помощью коэффициента детерминации, вообще говоря, некорректно. Для этих целей можно использовать альтернативные показатели.
Скорректированный (adjusted)
Для того, чтобы была возможность сравнивать модели с разным числом признаков так, чтобы число регрессоров (признаков) не влияло на статистику обычно используется скорректированный коэффициент детерминации, в котором используются несмещённые оценки дисперсий:
который даёт штраф за дополнительно включённые признаки, где — количество наблюдений, а
— количество параметров.
Данный показатель всегда меньше единицы, но теоретически может быть и меньше нуля (только при очень маленьком значении обычного коэффициента детерминации и большом количестве признаков), поэтому интерпретировать его как долю объясняемой дисперсии уже нельзя. Тем не менее, применение показателя в сравнении вполне обоснованно.
Для моделей с одинаковой зависимой переменной и одинаковым объемом выборки сравнение моделей с помощью скорректированного коэффициента детерминации эквивалентно их сравнению с помощью остаточной дисперсии или стандартной ошибки модели
.
Обобщённый (extended)
В случае отсутствия в линейной множественной МНК регрессии константы свойства коэффициента детерминации могут нарушаться для конкретной реализации. Поэтому модели регрессии со свободным членом и без него нельзя сравнивать по критерию . Эта проблема решается с помощью построения обобщённого коэффициента детерминации
, который совпадает с исходным для случая МНК регрессии со свободным членом. Суть этого метода заключается рассмотрении проекции единичного вектора на плоскость объясняющих переменных.
Для случая регрессии без свободного члена:
где — матрица
значений признаков,
— проектор на плоскость
,
,
— единичный вектор
.
При некоторой модификации также подходит для сравнения между собой регрессионных моделей, построенных с помощью: МНК, обобщённого метода наименьших квадратов (ОМНК), условного метода наименьших квадратов (УМНК), обобщённо-условного метода наименьших квадратов (ОУМНК).
