Прогнозирование объемов продаж групп товаров (отчет)
Материал из MachineLearning.
(→Описание системы) |
(→Описание системы) |
||
| Строка 256: | Строка 256: | ||
== Описание системы == | == Описание системы == | ||
| - | * Описание системы: [https://mlalgorithms.svn.sourceforge.net/svnroot/mlalgorithms/Ostrovskiy2009Groups/Docs/Systemdocs_Groups.doc]. | + | * Описание системы: [https://mlalgorithms.svn.sourceforge.net/svnroot/mlalgorithms/Group674/Ostrovskiy2009Groups/Docs/Systemdocs_Groups.doc]. |
| - | * Файлы системы находятся в папке [https://mlalgorithms.svn.sourceforge.net/svnroot/mlalgorithms/Ostrovskiy2009Groups]. | + | * Файлы системы находятся в папке [https://mlalgorithms.svn.sourceforge.net/svnroot/mlalgorithms/Group674/Ostrovskiy2009Groups]. |
== Отчет о вычислительных экспериментах == | == Отчет о вычислительных экспериментах == | ||
Текущая версия
Введение в проект
Описание проекта
Цель проекта
Цель проекта — прогнозирование еженедельных покупок товаров. Горизонт прогнозирования — одна неделя.
Обоснование проекта
Полученные результаты могут быть использованы для планирования закупок товаров магазинами.
Описание данных
Дан региональный классификатор магазинов, товарный классификатор, ряды продаж по SKU (stock keeping unit), информация о дефиците товара, список праздничных дней, разметка промо-акций для каждого товара и розничные цены на товары.
Критерии качества
Используется скользящий контроль — прогноз закупок товаров, сделанный исходя из данных на некотором начальном временном интервале, сравнивается с реальными продажами. Критерием качества служит сумма модулей отклонений прогноза от реальной величины закупок либо сумма квадратов отклонений.
Требования к проекту
Сумма модулей (либо квадратов) отклонений для разработанного алгоритма должен быть меньше, чем для базового алгоритма — скользящего среднего за предыдущий месяц.
Выполнимость проекта
Прогнозирование покупок товаров в празничные дни и во время промо-акций является отдельной задачей и в данном проекте не рассматривается.
Используемые методы
Предполагается, что товары могут быть агрегированы в группы, исходя из их цены и «близости» по товарному классификатору. Затем может быть осуществлен прогноз для получившихся групп товаров и «разбрасывание» результатов прогнозирования по отдельным товарам из групп.
Постановка задачи
Заданы временные ряды продаж товаров — продажи
-ого товара в
-ом магазине за день
(
,
— множество товаров;
,
— множество магазинов;
— натуральное число),
причем значения продаж известны при
. Также задан товарный классификатор, исходя из которого товары
разбиваются на группы, образующие иерархическую стуктуру (например, какой-то товар может
входить в группу «ЖК-телевизоры 15"», которая входит в
«ЖК-телевизоры 10" - 17"» и далее в «ЖК-телевизоры», «Телевизоры» и «Бытовую технику»).
Требуется для всех товаров и всех магазинов спрогнозировать продажи за неделю, следующую
после
, то есть значение величины
Для оценки качества прогнозов будем использовать скользящий контроль,
помещая в обучающую выборку значения при
,
. Как функционал качества будем использовать
или
Описание алгоритмов
Обзор литературы
Для прогноза спроса товаров в настоящее время используются различные: авторегрессия (autoregression, или AR), алгоритмы, основанные на модели скользящего среднего (moving average model, MA), их комбинации (ARMA и ARIMA) ([1], [2]), нейронные сети ([3], [4]). Однако в данной задаче количество временных рядов очень велико, что ограничивает возможные алгоритмы наиболее простыми, такими как скользящее среднее.
Базовые предположения
Будем предполагать, что вероятности продажи товаров из одной группы нижнего уровня (т.е. группы, в которую входят только товары, а не другие группы) во всех магазинах имеют одинаковое распределение. Таким образом, оценив это распределение, а также суммарные продажи всех товаров из группы нижнего уровня в некотором магазине (например, с помощью скользящего среднего), можно будет спрогнозировать продажи отдельных товаров точнее, чем используя базовый алгоритм (скользящее среднее по каждому товару). Также предполагается, что прогноз можно делать по отдельности для каждого из магазинов.
Математическое описание
Базовый алгоритм
Выбранный базовый алгоритм — скользящее среднее по каждому товару за предыдущий месяц:
где — ширина окна,
Алгоритм группового учета
1. Найти все группы нижнего уровня — разбиение множества на непересекающиеся подмножества
.
2. Для всех групп нижнего уровня повторять шаги 3-4:
3. Найти суммарные продажи товаров из во всех магазинах:
.
4. Определить доли продаж отдельных товаров из группы:
.
5. Повторять для всех и всех групп нижнего уровня
шаги 6-7:
6. Вычислить по методу скользящего среднего прогноз продаж товаров из в магазине
на следующую неделю:
7. Распределить предсказанное число товаров согласно величинам :
Варианты или модификации
Ширина окна при усреднении
Вышеприведенный алгоритм использует усреднение два раза — при вычислении и
. Длина окна, которая при этом используется, не обязана совпадать — в общем случае
. Этому можно дать простое объяснение: покупатели могут изменять предпочтения в пределах
группы товаров медленнее или, наоборот, быстрее, чем меняется суммарный спрос на товары из группы.
Обе длины
и
лучше всего определить с помощью скользящего контроля.
Дискретное количество товаров
В случае, если целые (и такими должны быть прогнозы
),
алгоритм требует модификации. Существует несколько способов добиться целых значений
:
- Округлять полученные на последнем шаге алгоритма прогнозы.
- Случайно распределять
товаров в соответствии с вероятностями
.
- Алгоритм RndDistribute (частичная рандомизация):
1. Из товаров определенную часть распределить детерминированно по формуле
где .
2. Подсчитать оставшееся количество товаров:
3. Пересчитать распределение товаров:
4. Распределить оставшиеся товары случайно согласно вероятностям .
В частности, при этот метод совпадает с предыдущим.
- Алгоритм MaxDistribute (полностью детерминированный вариант предыдущего метода):
1. Распределить максимально возможное количество товаров согласно вероятностям
2. Подсчитать оставшееся количество товаров:
3. Пересчитать распределение товаров:
4. Оставшиеся товары распределить по одному среди типов товаров с максимальными вероятностями .
Заметим, что алгоритм корректен, так как в любом случае .
Оценки качества
Как отмечено ранее, для оценки качества предлагается использовать сумму модулей или квадратов отклонений прогноза от дейсвительных продаж. Однако эти функционалы качества отдают предпочтение прогнозам с меньшими количествами продаж, так как верхняя грань обоих функционалов зависит от суммарных прогнозируемых продаж:
Таким образом, лучше в качестве функционалов использовать соотношения:
Разумеется, даже при таком подходе совершенно не учитывается взаимозаменяемость родственных товаров и т.п., что выходит за рамки сформулированной задачи.
Кластеризация магазинов
Исходный алгоритм был сформулирован в предположении, что распределение товаров одинаково во всех магазинах. В более общем случае магазины разбиваются на кластеры, исходя из выборочных значений распределения товаров. Модифицированный таким образом алгоритм будет иметь следующий вид:
1. Найти все группы нижнего уровня --- разбиение множества на непересекающиеся подмножества
.
2. Для каждого магазина вычислить распределение товаров
:
Используемая длина окна в общем случае отличается от
и
— большие значения
обеспечивают большую статистическую надежность (особенно при небольшом спросе на товары). С другой стороны, при слишком больших длинах не учитывается изменение распределения с временем. Оптимальное
находится с помощью скользящего контроля.
3. Вычислить расстояние между всеми парами распределений и
. В качестве метрики можно использовать метрику
либо
4. Исходя из расстояний, разбить магазины на кластеров. Оптимальное
также находится с помощью скользящего контроля. Заметим, что при
алгоритм превращается в алгоритм группового учета, а при
— в базовый алгоритм.
5. Для каждого из кластеров применить шаги 2-7 алгоритма группового учета.
Теоретически, кластеризация магазинов может помочь при прогнозировании продаж товаров во время промо-акций, разделяя магазины, в которых проводятся или не проводятся промо-акции, в разные кластеры. Практически, возможности кластеризации ограничены из-за так называемого «проклятия размерности» (curse of dimensions).
Работа с промо-акциями
Продажи товаров во время промо-акций можно либо интерпретировать, как и продажи остальных товаров, либо игнорировать, принимая равными нулю.
Описание системы
Отчет о вычислительных экспериментах
Сравнение алгоритма с базовым
Сравнивались предсказания базового алгоритма и алгоритма группового учета с параметрами (т.е. кластеризация магазинов не проводилась),
,
. Для получения целочисленных предсказаний использовались: в случае базового алгоритма — простое округление, в случае алгоритма группового учета — алгоритм MaxDistribute, описанный ранее. Оценка качества проводилась с помощью скользящего контроля, при котором верхняя граница обучающей выборки
последовательно принимала 120 разных значений с интервалом в 5 дней. Использовались функционалы качества
и
.
Результаты работы приведены на рисунках ниже (зависимости качества от
; базовый алгоритм обозначен синим цветом, наш алгоритм — зеленым) и таблице.




| Функционал | Алгоритм | Промо-акции оставлены | Промо-акции обнулены |
|---|---|---|---|
| | базовый | 64.9% | 67.5% |
| | групповой | 60.2% | 62.7% |
| | базовый | 62.2% | 61.0% |
| | групповой | 58.1% | 57.3% |
Видно, что независимо от функционала качества и способа учета промо-акций алгоритм группового учета более эффетивен, чем базовый алгоритм. Тем не менее, значения функционалов качества все равно довольно велики и для нашего алгоритма. Это связано с тем, что продажи даже самых покупаемых товаров в отдельных магазинах малы и испытывают большие флуктуации.
Зависимость работы алгоритма от параметров
Зависимость от способа округления
Выше были приведены три способа получения целочисленных прогнозов: простое округление, рандомизация и алгоритм MaxDistribute. Для выбора предпочтительного метода использовался скользящий контроль, при котором верхняя граница обучающей выборки последовательно принимала 60 значений с интервалом в 10 дней; затем значения функционалов качества усреднялись.


| Функционал | Метод | Промо-акции оставлены | Промо-акции обнулены |
|---|---|---|---|
| | округление | 62.1% | 65.0% |
| | рандомизация | 65.6% | 68.7% |
| | MaxDistribute | 60.2% | 62.7% |
| | округление | 60.0% | 59.7% |
| | рандомизация | 62.1% | 62.9% |
| | MaxDistribute | 58.1% | 57.1% |
Во всех случаях лучшим оказался метод MaxDistribute, далее следует простое округление, а хуже всех — рандомизация.
Зависимость от  и
и 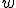
Для оценки качества при разных значениях параметров и
использовался скользящий контроль, как и в предыдущем пункте.
менялось от 3 до 30 дней с шагом в 3 дня, при этом полагалось
,
.
менялось от 3 до 60 дней с шагом в 3 дня, полагалось
,
. Продажи во время промо-акций не занулялись (при занулении результаты аналогичны).
Результаты работы приведены ниже (синим обозначен функционал качества , красным —
). Видно, что качество прогнозов сильно зависит от
, причем оптимальными являются минимальные значения (хотя это сложно обосновать теоретически). От
качество зависит менее выраженно; оптимальными можно считать значения
.


Зависимость от количества кластеров 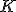
При варьировании верхняя граница обучающей выборки
последовательно принимала 13 значений с интервалом в 50 дней. Полагалось
,
,
; для кластеризации использовалась метрика
.
Результаты приведены в таблице.
| Промо-акции | Функционал | |||||
|---|---|---|---|---|---|---|
| оставлены | | 60.48% | 60.44% | 60.61% | 60.43% | 60.84% |
| оставлены | | 56.19% | 56.01% | 56.17% | 55.83% | 56.25% |
| обнулены | | 63.33% | 63.32% | 63.25% | 63.49% | 63.51% |
| обнулены | | 57.30% | 57.13% | 57.07% | 57.02% | 57.35% |
Зависимость от 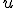
При варьировании верхняя граница обучающей выборки
последовательно принимала 13 значений с интервалом в 50 дней. Величина
менялась от 20 до 90 с шагом 10 дней. Полагалось
,
,
. Результаты — на рисунке ниже (промо-акции оставлены; при обнулении результаты мало отличаются).

Видно, что качество прогнозов мало зависит от количества кластеров и . Это связано с «проклятием размерности» и несовершенством выбранной для кластеризации метрики.
Отчет о полученных результатах
Список литературы
- P. Cortez, M. Rocha, J.Neves. Time Series Forecasting ARMA Models.
- R. Nochai, T. Nochai. Model for Forecasting Oil Palm Price.
- F. M. Thiesing, O. Vornberger. Sales Using Neural Networks.
- I. A. Gheyas, L. S. Smith. Neural Network Approach to Time Series Forecasting.
| | Данная статья была создана в рамках учебного задания.
См. также методические указания по использованию Ресурса MachineLearning.ru в учебном процессе. |
