Биномиальное распределение
Материал из MachineLearning.
(→Определение) |
м |
||
| (6 промежуточных версий не показаны.) | |||
| Строка 20: | Строка 20: | ||
==Определение== | ==Определение== | ||
| - | ''Биномиальное распределение'' — дискретное распределение вероятностей | + | ''Биномиальное распределение'' — дискретное распределение вероятностей [[случайная_величина|случайной величины]] <tex>X,</tex> принимающей целочисленные значения <tex>k=0,1,\ldots,n</tex> с вероятностями: |
::<tex>P(X=k)={n \choose k}p^k(1-p)^{n-k}.</tex> | ::<tex>P(X=k)={n \choose k}p^k(1-p)^{n-k}.</tex> | ||
| Строка 120: | Строка 120: | ||
*[http://ru.wikipedia.org/wiki/%D0%91%D0%B8%D0%BD%D0%BE%D0%BC%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D1%80%D0%B0%D1%81%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5 Биномиальное распределение] (Википедия) | *[http://ru.wikipedia.org/wiki/%D0%91%D0%B8%D0%BD%D0%BE%D0%BC%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D1%80%D0%B0%D1%81%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5 Биномиальное распределение] (Википедия) | ||
*[http://en.wikipedia.org/wiki/Binomial_distribution Binomial distribution] (Wikipedia) | *[http://en.wikipedia.org/wiki/Binomial_distribution Binomial distribution] (Wikipedia) | ||
| - | |||
| - | |||
| - | |||
| - | |||
| - | |||
| - | |||
| - | |||
| - | |||
| - | |||
[[Категория:Вероятностные распределения]] | [[Категория:Вероятностные распределения]] | ||
Текущая версия
Функция вероятности
| |
Функция распределения
| |
| Параметры | |
| Носитель | |
| Функция вероятности | |
| Функция распределения | |
| Математическое ожидание | |
| Медиана | одно из |
| Мода | |
| Дисперсия | |
| Коэффициент асимметрии | |
| Коэффициент эксцесса | |
| Информационная энтропия | |
| Производящая функция моментов | |
| Характеристическая функция | |
Содержание |
Определение
Биномиальное распределение — дискретное распределение вероятностей случайной величины принимающей целочисленные значения
с вероятностями:
Данное распределение характеризуется двумя параметрами: целым числом называемым числом испытаний, и вещественным числом
называемом вероятностью успеха в одном испытании. Биномиальное распределение — одно из основных распределений вероятностей, связанных с последовательностью независимых испытаний. Если проводится серия из
независимых испытаний, в каждом из которых может произойти "успех" с вероятностью
то случайная величина, равная числу успехов во всей серии, имеет указанное распределение. Эта величина также может быть представлена в виде суммы
независимых слагаемых, имеющих распределение Бернулли.
Основные свойства
- Математическое ожидание:
- Дисперсия:
- Асимметрия:
при
распределение симметрично относительно центра
Асимптотические приближения при больших 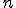
Если значения велики, то непосредственное вычисление вероятностей событий, связанных с данной случайной величиной, технически затруднительно.
В этих случаях можно использовать приближения биномиального распределения распределением Пуассона и нормальным (приближение Муавра-Лапласа).
Приближение Пуассона
Приближение распределением Пуассона применяется в ситуациях, когда значения большие, а значения
близки к нулю. При этом биномиальное распределение аппроксимируется распределением Пуассона с параметром
Строгая формулировка: если и
таким образом, что
то
Более того, справедлива следующая оценка. Пусть — случайная величина, имеющая распределение Пуассона с параметром
Тогда для произвольного множества
справедливо неравенство:
Доказательство и обзор более точных результатов, касающихся точности данного приближения, можно найти в [1, гл. III, §12].
Нормальное приближение
Приближение нормальным распределением используется в ситуациях, когда а
фиксировано. Это приближение можно рассматривать как частный случай центральной предельной теоремы, применение которой основано на представлении
в виде суммы
слагаемых. Приближение основано на том, что при указанных условиях распределение нормированной величины
где
близко к стандартному нормальному.
Локальная теорема Муавра-Лапласа
Данная теорема используется для приближенного вычисления вероятностей отдельных значений биномиального распределения. Она утверждает [1, гл. I, §6], что равномерно по всем значениям таким что
имеет место
где — плотность стандартного нормального распределения.
Интегральная теорема Муавра-Лапласа
На практике необходимость оценки вероятностей отдельных значений, которую дает локальная теорема Муавра-Лапласа, возникает нечасто. Гораздо более важно оценивать вероятности событий, включающих в себя множество значений. Для этого используется интегральная теорема, которую можно сформулировать в следующем виде [1, гл. I, §6]:
при
где случайная величина имеет стандартное нормальное распределение
и аппроксимирующая вероятность определяется по формуле
где — функция распределения стандартного нормального закона:
Есть ряд результатов, позволяющих оценить скорость сходимости. В [1, гл. I, §6] приводится следующий результат, являющийся частным случаем теоремы Берри-Эссеена:
где — функция распределения случайной величины
На практике решение о том, насколько следует доверять нормальному приближению, принимают исходя из величины
Чем она больше, тем меньше будет погрешность приближения.
Заметим, что асимптотический результат не изменится, если заменить строгие неравенства на нестрогие и наоборот. Предельная вероятность от такой замены также не поменяется, так как нормальное распределение абсолютно непрерывно и вероятность принять любое конкретное значение для него равна нулю. Однако исходная вероятность от такой замены может измениться, что вносит в формулу некоторую неоднозначность. Для больших значений изменение будет невелико, однако для небольших
это может внести дополнительную погрешность.
Для устранения этой неоднозначности, а также повышения точности приближения рекомендуется задавать интересующие события в виде интервалов с полуцелыми границами. При этом приближение получается точнее. Это связано с тем интуитивно понятным соображением, что аппроксимация кусочно-постоянной функции (функции распределения биномиального закона) с помощью непрерывной функции дает более точные приближения между точками разрыва, чем в этих точках.
Пример
Пусть
Оценим вероятность того, что число успехов будет отличаться от наиболее вероятного значения
не более чем на
. Заметим, что значение
очень мало, поэтому применение нормального приближения здесь довольно ненадежно.
Точная вероятность рассматриваемого события равна
Применим нормальное приближение с той расстановкой неравенств, которая дана выше (снизу строгое, сверху нестрогое):
Ошибка приближения равна .
Теперь построим приближение, используя интервал с концами в полуцелых точках:
Ошибка приближения равна — примерно в 5 раз меньше, чем в предыдущем подходе.
Литература
1. Ширяев А.Н. Вероятность. — М.: МЦНМО, 2004.
Ссылки
- Биномиальное распределение (Википедия)
- Binomial distribution (Wikipedia)
