Робастное оценивание
Материал из MachineLearning.
| Строка 12: | Строка 12: | ||
=== Оценки типа максимального правдоподобия (<tex>M-</tex>оценки)=== | === Оценки типа максимального правдоподобия (<tex>M-</tex>оценки)=== | ||
| + | Всякая оценка <tex>T_n</tex> | ||
| + | |||
| + | <tex>\sum_{i=1}^n \rho (x_i;T_n) \rightarrow \min</tex> | ||
| + | |||
| + | <tex>\sum_{i=1}^n \psi (x_i;T_n) = 0</tex> | ||
== Вычисление робастных оценок == | == Вычисление робастных оценок == | ||
Версия 20:18, 5 января 2010
Содержание |
Введение
На протяжении последних десятилетий росло понимание того факта, что некоторые наиболее распространенные статистические процедуры (в том числе те, которые оптимальны в предположении о нормальности распределения) весьма чувствительны к довольно малым отклонениям от предположений. Вот почему теперь появились иные процедуры - "робастные" (от англ. robust - крепкий,здоровый, дюжий).
Мы будем понимать под термином робастность нечувствительность к малым отклонениям от предположений. Процедура робастна, если малые отклонения от предположенной модели должны ухудшать качество процедуры (например, асимптотика дисперсии или уровень значимости и мощность критерия) должны быть близки к номинальным величинам, вычисленным для принятой модели.
Рассмотрим робастность по распределению, т.е. ситуации, в которых истинная функция распределения незначительно отличается от предполагаемой в модели (как правило, гауссовской функции распределения). Это не только наиболее важный случай, но и наиболее полно изученный. Гораздо меньше известно о том, что происходит в тех ситуациях, когда несколько нарушаются прочие стандартные допущения статистики, и том, какие меры защиты должны предусматриваться в подобных случаях.
Основные типы оценок
Введем оценки трех основных типов (),буквы
отвечают соответственно оценкам типа максимального правдоподобия, линейным комбинациям порядковых статистик и оценкам, получаемых в ранговых критериях.
Особое значение имеют оценки, это наиболее гибкие оценки - они допускают прямое обобщение на многопараметрический случай.
Оценки типа максимального правдоподобия (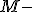 оценки)
оценки)
Всякая оценка
Вычисление робастных оценок
Рассмотрим пример. Для оценки неизвестных параметров
используется
наблюдений
, причем они связаны между собой следующим неравенством
, где элементы матрицы
суть известные коэффициенты, а
- вектор независимых случайных величин,имеющих (приблизительное)одинаковые функции распределения.
Тогда решение сводится к следующему:
Если матрица - матрица полного ранга
, то
,
а оценки
будут высиляться по следующей формуле
,
где
, далее
- матрица подгонки.
Допустим, что мы получили значения и остатки
.
Пусть - некоторая оценка стандартной ошибки наблюдений
(или стандартной ошибки остатков
)
Метрически винзоризуем наблюдения , заменяя их псевдонаблюдениями
:
Константа регулирует степень робастности, её значения хорошо выбирать из промежутка от 1 до 2, например, чаще всего
.
Затем по псевдонаблюдениям вычисляются новые значения
подгонки (и новые
).
Действия повторяются до достижения сходимости.
Если все наблюдения совершенно точны, то классическая оценка дисперсии отдельного наблюдения имеет вид
,
и стандартную ошибку остатка
можно в этом случае оценивать величиной
, где
есть
-й диагональный элемент матрицы
.
При использовании вместо остатков модифицированных остатков
, как нетрудно видеть, получается заниженная оценка масштаба. Появившееся смещение можно ликвидировать, полагая (в первом приближении)
,
где - число наблюдений без числа параметров,
- число неизменных наблюдений (
).
Очевидно, что эта процедура сводит на нет влияние выделяющихся наблюдений.
Литература
- Хьюбер П. Робастность в статистике. — М.: Мир, 1984.
Ссылки
- Робастность в статистике.
- Робастность статистических процедур.
- Публикации по робастным методам оценивания параметров и проверке статистических гипотез на сайте профессора НГТУ Лемешко Б.Ю..
- Robust statistics.
См. также
| | Данная статья является непроверенным учебным заданием.
До указанного срока статья не должна редактироваться другими участниками проекта MachineLearning.ru. По его окончании любой участник вправе исправить данную статью по своему усмотрению и удалить данное предупреждение, выводимое с помощью шаблона {{Задание}}. См. также методические указания по использованию Ресурса MachineLearning.ru в учебном процессе. |
