Алгоритм LOWESS
Материал из MachineLearning.
| | Статья плохо доработана. Имеются указания по её улучшению: |

Алгоритм LOWESS (locally weighted scatter plot smoothing) - локально взвешенное сглаживание.
Содержание |
Введение
- Данная методика была предложена Кливлендом(Cleveland) в 1979 году для моделирования и сглаживания двумерных данных
.
Эта техника предоставляет общий и гибкий подход для приближения двумерных данных.
- Локально линейная модель loess(lowess) можеть быть записана в виде:
- Эта модель может быть расширена на случай локально-квадратичной зависимости и на модель с больши'м числом независимых переменных.
- Параметры
и
локально линейной модели оцениваются, с помощью локально взвешенной регрессии, которая присваивает объекту тем больший вес, чем более близок он близким к объекту
. Характер
взвешивания определяется с помощью параметра сглаживания , который выбирает пользователь.
- Параметр
какая указывает доля данных используется в процедуре. Если
, то только половина данных используется для оценки и влияет на результат, и тогда мы получим умеренное сглаживание. С другой стороны, если
, то используются восемьдесят процентов данных, и сглаживание намного сильнее. Во всех случаях веса данных
тем больше чем они ближе к объекту .
- Процедура оценки использует не метод наименьших квадратов, а более устойчивый(робастный) метод, который принимает меры против выбросов.
График приближенных значений
против полезен для подведения итогов о связи между
и
. Для проверки качества приближения полученного с помощью процедуры устойчивого loess полезно посмотреть на график остатков обычной регресссии, то есть в осях (i) остатки против числа наблюдения (ii) остатки против приближенных значений, (iii) остатки против значений независимой переменной. Как показал Кливленд, может быть предпочтительно использовать график в осях модули остатков против полученных приближенных значений вместо графика (ii) для устойчивого loess сглаживания, чтобы проверить наличие тренда или других систематических особенностей.
Когда вычисления могут быть слишком долгими, в этом случае можно сократить количество вычислений оценивая
и
только в
точках отстоящих друг от друга как минимум на
единиц, где параметр
может задаваться либо приниматься по умолчанию. Рекомендуемые значения
Если
Если
, где
- межквартильных размах(Interquartile range).
С такими параметрами вычисления будут выполнены для примерно 100 точек.
Примеры
| Переменная | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X | 130 | 225 | 95 | 100 | 170 | 65 | 175 | 130 | 80 | 150 | 150 | 107 | 122 | 110 | 52 | 72 | 110 | 97 | 92 | 90 | 70 | 130 | 130 | 88 | 48 | 85 | 139 | 103 | 110 | 65 |
| Y | 18 | 14 | 25 | 19 | 13 | 31 | 14 | 13 | 28 | 14 | 11 | 21 | 20 | 16 | 31 | 15 | 21 | 18 | 25 | 23 | 32 | 13 | 15 | 25 | 43 | 20 | 18 | 20 | 21 | 34 |


Решается задача восстановления регрессии. Задано пространство объектов и множество возможных
ответов
. Существует неизвестная целевая зависимость
,
значения которой известны только на объектах обучающей выборки .
Требуется построить алгоритм
, аппроксимирующий целевую зависимость
.
Непараметрическая регрессия
- Непараметрическое восстановление регрессии основано на идее, что значение
вычисляется
для каждого объекта по нескольким ближайшим к нему объектам обучающей выборки.
В формуле Надарая–Ватсона для учета близости объектов обучающей выборки к объекту
предлагалось использовать невозрастающую, гладкую, ограниченную функцию
, называемую ядром:
Параметр называется шириной ядра или шириной окна сглаживания. Чем меньше
,
тем быстрее будут убывать веса
по мере удаления
от
.
В общем случае
зависит от объекта
, т.е.
. Тогда веса вычисляются по формуле
Оптимизация ширины окна
Чтобы оценить при данном и
точность локальной аппроксимации в точке
,
саму эту точку необходимо исключить из обучающей выборки. Если этого не делать, минимум ошибки будет
достигаться при
. Такой способ оценивания оптимальной ширины окна называется скользящим контролем
с исключением объектов по одному (leave-one-out, LOO):
Проблема выбросов
- Оценка Надарайя–Ватсона
крайне чувствительна к большим одиночным выбросам. На практике легко идентифицируются только грубые ошибки, возникающие, например, в результате сбоя оборудования или невнимательности персонала при подготовке данных. В общем случае можно лишь утверждать, что чем больше величина ошибки
тем в большей степени прецедент является выбросом , и тем меньше должен быть его вес.
Эти соображения приводят к идее домножить веса
на коэффициенты
, где
— ещё одно ядро, вообще говоря,
отличное от
.
Алгоритм LOWESS
Вход
- обучающая выборка;
весовые функции;
Выход
Коэффициенты
Алгоритм
- 1: инициализация
- 2: повторять
- 3: вычислить оценки скользящего контроля на каждом объекте:
- 4: вычислить новые значения коэффициентов
:
;
- 5: пока коэффициенты
Коэффициенты , как и ошибки
, зависят от функции
, которая,
в свою очередь, зависит от
. На каждой итерации строится функция
,
затем уточняются весовые множители
. Как правило, этот процесс сходится довольно быстро.
Он называется локально взвешенным сглаживанием (locally weighted scatter plot smoothing, LOWESS).
Выбор ядра 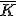
- В качестве ядра
Пусть - есть медиана коэффициентов
,
тогда
, где
Более простой вариант, состоит в отбросе коэффициентов, соответствующих объектам с максимальными
. Это соотвествует ядру
где –-
- тый член вариационного ряда
Примеры применения
Литература
- Воронцов К.В. Лекции по алгоритмам восстановления регрессии. — 2007.
- A.I. McLeod Statistics 259b Robust Loess: S lowess. — 2004.
- John A Berger, Sampsa Hautaniemi, Anna-Kaarina Järvinen, Henrik Edgren, Sanjit K Mitra and Jaakko Astola Optimized LOWESS normalization parameter selection for DNA microarray data. — BMC Bioinformatics, 2004.
См. также
- Непараметрическая регрессия
- Регрессионный анализ
- Local regression
- Расин, Джеффри (2008) «Непараметрическая эконометрика: вводный курс», Квантиль, №4, стр. 7–56.
| | Данная статья является непроверенным учебным заданием.
До указанного срока статья не должна редактироваться другими участниками проекта MachineLearning.ru. По его окончании любой участник вправе исправить данную статью по своему усмотрению и удалить данное предупреждение, выводимое с помощью шаблона {{Задание}}. См. также методические указания по использованию Ресурса MachineLearning.ru в учебном процессе. |
→
