Метод главных компонент
Материал из MachineLearning.
(→Примечания) |
(→Аппроксимация данных линейными многообразиями) |
||
| Строка 17: | Строка 17: | ||
[[Изображение:PearsonFig.jpg|thumb|Иллюстрация к знаменитой работе К. Пирсона (1901): даны точки <tex> P_i</tex> на плоскости, <tex> p_i</tex> — расстояние от <tex> P_i</tex> до прямой <tex> AB</tex>. Ищется прямая <tex> AB</tex>, минимизирующая сумму <tex>\sum_i p_i^2</tex> ]] | [[Изображение:PearsonFig.jpg|thumb|Иллюстрация к знаменитой работе К. Пирсона (1901): даны точки <tex> P_i</tex> на плоскости, <tex> p_i</tex> — расстояние от <tex> P_i</tex> до прямой <tex> AB</tex>. Ищется прямая <tex> AB</tex>, минимизирующая сумму <tex>\sum_i p_i^2</tex> ]] | ||
| - | Метод главных компонент начинался с задачи наилучшей аппроксимации конечного множества точек прямыми и плоскостями (К. Пирсон, 1901). Дано конечное множество | + | Метод главных компонент начинался с задачи наилучшей аппроксимации конечного множества точек прямыми и плоскостями (К. Пирсон, 1901). Дано конечное множество векторов <tex>x_1,x_2,...x_m \in\mathbb{R}^n </tex>. Для каждого <tex> k = 0,1,..., n-1 </tex> среди всех <tex>k</tex>-мерных линейных многообразий в <tex>\mathbb{R}^n </tex> найти такое <tex>L_k \subset \mathbb{R}^n </tex>, что сумма квадратов уклонений <tex> x_i</tex> от <tex> L_k</tex> минимальна: |
: <tex>\sum_{i=1}^m \operatorname{dist}^2(x_i, L_k) \to \min</tex>, | : <tex>\sum_{i=1}^m \operatorname{dist}^2(x_i, L_k) \to \min</tex>, | ||
где <tex>\operatorname{dist}(x_i, L_k) </tex> — евклидово расстояние от точки до линейного многообразия. Всякое <tex>k </tex>-мерное линейное многообразие в <tex>\mathbb{R}^n </tex> может быть задано как множество линейных комбинаций <tex>L_k = \{ a_0 +\beta_1 a_1 +...+ \beta_k a_k | \beta_i \in \mathbb{R} \} </tex>, где параметры <tex> \beta_i </tex> пробегают вещественную прямую <tex>\mathbb{R}</tex>, <tex>a_0 \in \mathbb{R}^n</tex> а <tex>\left\{a_1,..., a_k \right\} \subset \mathbb{R}^n</tex> — ортонормированный набор векторов | где <tex>\operatorname{dist}(x_i, L_k) </tex> — евклидово расстояние от точки до линейного многообразия. Всякое <tex>k </tex>-мерное линейное многообразие в <tex>\mathbb{R}^n </tex> может быть задано как множество линейных комбинаций <tex>L_k = \{ a_0 +\beta_1 a_1 +...+ \beta_k a_k | \beta_i \in \mathbb{R} \} </tex>, где параметры <tex> \beta_i </tex> пробегают вещественную прямую <tex>\mathbb{R}</tex>, <tex>a_0 \in \mathbb{R}^n</tex> а <tex>\left\{a_1,..., a_k \right\} \subset \mathbb{R}^n</tex> — ортонормированный набор векторов | ||
| - | : <tex>\operatorname{dist}^2(x_i, L_k) = \ | + | : <tex>\operatorname{dist}^2(x_i, L_k) = \| x_i - a_0 - \sum_{j=1}^k a_j (a_j, x_i - a_0) \| ^2</tex>, |
| - | где <tex>\ | + | где <tex>\| \cdot \| </tex> евклидова норма, <tex> \left(a_j, x_i\right) </tex> — евклидово скалярное произведение, или в координатной форме: |
: <tex> \operatorname{dist}^2(x_i, L_k) = \sum_{l=1}^n \left(x_{il} - a_{0l}- \sum_{j=1}^k a_{jl} \sum_{q=1}^n a_{jq}(x_{iq} - a_{0q}) \right)^2 </tex>. | : <tex> \operatorname{dist}^2(x_i, L_k) = \sum_{l=1}^n \left(x_{il} - a_{0l}- \sum_{j=1}^k a_{jl} \sum_{q=1}^n a_{jq}(x_{iq} - a_{0q}) \right)^2 </tex>. | ||
| Строка 33: | Строка 33: | ||
то есть | то есть | ||
| - | : <tex>a_0 = \underset{a_0\in\mathbb{R}^n}{\operatorname{argmin}} \left (\sum_{i=1}^m \ | + | : <tex>a_0 = \underset{a_0\in\mathbb{R}^n}{\operatorname{argmin}} \left (\sum_{i=1}^m \| x_i - a_0\| ^2\right) </tex>. |
Это — [[выборочное среднее]]: <tex>a_0 = \frac{1}{m} \sum_{i=1}^m x_i = \overline{X}.</tex> | Это — [[выборочное среднее]]: <tex>a_0 = \frac{1}{m} \sum_{i=1}^m x_i = \overline{X}.</tex> | ||
| Строка 41: | Строка 41: | ||
: 1) централизуем данные (вычитаем среднее): <tex>x_i := x_i - \overline{X_i}</tex>. Теперь <tex>\sum_{i=1}^m x_i =0 </tex>; | : 1) централизуем данные (вычитаем среднее): <tex>x_i := x_i - \overline{X_i}</tex>. Теперь <tex>\sum_{i=1}^m x_i =0 </tex>; | ||
: 2) находим первую главную компоненту как решение задачи; | : 2) находим первую главную компоненту как решение задачи; | ||
| - | :: <tex>a_1 = \underset{\ | + | :: <tex>a_1 = \underset{\| a_1 \| =1}{\operatorname{argmin}} \left( \sum_{i=1}^m \| x_i - a_1 (a_1,x_i)\| ^2\right)</tex>. |
:: Если решение не единственно, то выбираем одно из них. | :: Если решение не единственно, то выбираем одно из них. | ||
: 3) Вычитаем из данных проекцию на первую главную компоненту: | : 3) Вычитаем из данных проекцию на первую главную компоненту: | ||
:: <tex>x_i := x_i - a_1 \left(a_1,x_i\right) </tex>; | :: <tex>x_i := x_i - a_1 \left(a_1,x_i\right) </tex>; | ||
: 4) находим вторую главную компоненту как решение задачи | : 4) находим вторую главную компоненту как решение задачи | ||
| - | :: <tex>a_2 = \underset{\ | + | :: <tex>a_2 = \underset{\| a_2 \| =1}{\operatorname{argmin}} \left( \sum_{i=1}^m \| x_i - a_2 (a_2,x_i)\| ^2\right) </tex>. |
:: Если решение не единственно, то выбираем одно из них. | :: Если решение не единственно, то выбираем одно из них. | ||
:: … | :: … | ||
| Строка 52: | Строка 52: | ||
:: <tex>x_i := x_i - a_{k-1} \left(a_{k-1},x_i\right) </tex>; | :: <tex>x_i := x_i - a_{k-1} \left(a_{k-1},x_i\right) </tex>; | ||
: 2k) находим k-ю главную компоненту как решение задачи: | : 2k) находим k-ю главную компоненту как решение задачи: | ||
| - | :: <tex>a_k = \underset{\ | + | :: <tex>a_k = \underset{\| a_k \| =1}{\operatorname{argmin}} \left( \sum_{i=1}^m \| x_i - a_k (a_k,x_i)\| ^2\right) </tex>. |
:: Если решение не единственно, то выбираем одно из них. | :: Если решение не единственно, то выбираем одно из них. | ||
:: … | :: … | ||
Версия 23:49, 30 июня 2008
Метод Главных Компонент (англ. Principal Components Analysis, PCA) — один из основных способов уменьшить размерность данных, потеряв наименьшее количество информации. Изобретен К. Пирсоном (англ.Karl Pearson) в 1901 г. Применяется во многих областях, таких как распознавание образов, компьютерное зрение, сжатие данных и т. п. Вычисление главных компонент сводится к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных. Иногда метод главных компонент называют преобразованием Кархунена-Лоэва (англ. Karhunen-Loeve)[1] или преобразованием Хотеллинга (англ. Hotelling transform). Другие способы уменьшения размерности данных — это метод независимых компонент, многомерное шкалирование, а также многочисленные нелинейные обобщения: метод главных кривых и многообразий, поиск наилучшей проекции (англ. Projection Pursuit), нейросетевые методы «узкого горла», самоорганизующиеся карты Кохонена и др.
Формальная постановка задачи
| | Статья в настоящий момент дорабатывается. Agor153 03:21, 1 июля 2008 (MSD) |
Задача анализа главных компонент, имеет, как минимум, три базовых версии:
- аппроксимировать данные линейными многообразиями меньшей размерности;
- найти подпространства меньшей размерности, в ортогональной проекции на которые разброс данных максимален;
- для данной многомерной случайной величины построить такое ортогональное преобразования координат, что в результате корреляции между отдельными координатами обратятся в ноль.
Первые две версии оперируют конечными множествами данных. Они эквивалентны и не используют никакой гипотезы о статистическом порождении данных. Третья версия оперирует случайными величинами. Конечные множества появляются здесь как выборки из данного распределения, а решение двух первых задач — как приближение к «истинному» преобразованию Кархунена-Лоэва. При этом возникает дополнительный и не вполне тривиальный вопрос о точности этого приближения.
Аппроксимация данных линейными многообразиями

Метод главных компонент начинался с задачи наилучшей аппроксимации конечного множества точек прямыми и плоскостями (К. Пирсон, 1901). Дано конечное множество векторов . Для каждого
среди всех
-мерных линейных многообразий в
найти такое
, что сумма квадратов уклонений
от
минимальна:
-
,
где — евклидово расстояние от точки до линейного многообразия. Всякое
-мерное линейное многообразие в
может быть задано как множество линейных комбинаций
, где параметры
пробегают вещественную прямую
,
а
— ортонормированный набор векторов
-
,
где евклидова норма,
— евклидово скалярное произведение, или в координатной форме:
-
.
Решение задачи аппроксимации для даётся набором вложенных линейных многообразий
,
. Эти линейные многообразия определяются ортонормированным набором векторов
(векторами главных компонент) и вектором
.
Вектор
ищется, как решение задачи минимизации для
:
то есть
-
.
Это — выборочное среднее:
Фреше в 1948 году обратил внимание, что вариационное определение среднего (как точки, минимизирующей сумму квадратов расстояний до точек данных) очень удобно для построения статистики в произвольном метрическом пространстве, и построил обобщение классической статистики для общих пространств (обобщённый метод наименьших квадратов).
Векторы главных компонент могут быть найдены как решения однотипных задач оптимизации:
- 1) централизуем данные (вычитаем среднее):
. Теперь
;
- 2) находим первую главную компоненту как решение задачи;
-
.
- Если решение не единственно, то выбираем одно из них.
-
- 3) Вычитаем из данных проекцию на первую главную компоненту:
-
;
-
- 4) находим вторую главную компоненту как решение задачи
-
.
- Если решение не единственно, то выбираем одно из них.
- …
-
- 2k-1) Вычитаем проекцию на
-ю главную компоненту (напомним, что проекции на предшествующие
главные компоненты уже вычтены):
-
;
-
- 2k) находим k-ю главную компоненту как решение задачи:
-
.
- Если решение не единственно, то выбираем одно из них.
- …
-
На каждом подготовительном шаге вычитаем проекцию на предшествующую главную компоненту. Найденные векторы
ортонормированы просто в результате решения описанной задачи оптимизации, однако чтобы не дать ошибкам вычисления нарушить взаимную ортогональность векторов главных компонент, можно включать
в условия задачи оптимизации.
Неединственность в определении помимо тривиального произвола в выборе знака (
и
решают ту же задачу) может быть более существенной и происходить, например, из условий симметрии данных.
Поиск ортогональных проекций с наибольшим рассеянием

Пусть нам дан центрированный набор векторов данных (среднее арифметическое значение
равно нулю). Задача — найти такое ортогональное преобразование в новую систему координат, для которого были бы верны следующие условия:
- Выборочная дисперсия данных вдоль первой координаты максимальна (эту координату называют первой главной компонентой);
- Выборочная дисперсия данных вдоль второй координаты максимальна при условии ортогональности первой координате (вторая главная компонента);
- …
- Выборочная дисперсия данных вдоль значений
-ой координаты максимальна при условии ортогональности первым
координатам;
- …
Выборочная дисперсия данных вдоль направления, заданного нормированным вектором , это
(поскольку данные центрированы, выборочная дисперсия здесь совпадает со средним квадратом уклонения от нуля).
Формально, если ,
— искомое преобразование, то для векторов
должны выполняться следующие условия:
- Если решение не единственно, то выбираем одно из них.
- Вычитаем из данных проекцию на первую главную компоненту:
-
;
- находим вторую главную компоненту как решение задачи
-
- Если решение не единственно, то выбираем одно из них.
- …
- Вычитаем проекцию на
главные компоненты уже вычтены):
-
;
- находим
-
- Если решение не единственно, то выбираем одно из них.
- …
Фактически, как и для задачи аппроксимации, на каждом шаге решается задача о первой главной компоненте для данных, из которых вычтены проекции на все ранее найденные главные компоненты. При большом числе итерации (большая размерность, много главных компонент) отклонения от ортогональности накапливаются и может потребоваться специальная коррекция алгоритма или другой алгоритм поиска собственных векторов ковариационной матрицы.
Решение задачи о наилучшей аппроксимации даёт то же множество решений , что и поиск ортогональных проекций с наибольшим рассеянием, по очень простой причине:
и первое слагаемое не зависит от
. Только одно дополнение к задаче об аппроксимации: появляется последняя главная компонента
Поиск ортогональных проекций с наибольшим среднеквадратичным расстоянием между точками
Ещё одна эквивалентная формулировка следует из очевидного тождества, верного для любых векторов
:
В левой части этого тождества стоит среднеквадратичное расстояние между точками, а в квадратных скобках справа — выборочная дисперсия. Таким образом, в методе главных компонент ищутся подпространства, в проекции на которые среднеквадратичное расстояние между точками максимально. Такая переформулировка позволяет строить обобщения с взвешиванием различных парных расстояний (а не только точек).
Аннулирование корреляций между координатами
Для заданной -мерной случайной величины
найти такой ортонормированный базис,
, в котором коэффициент ковариации между различными координатами равен нулю. После преобразования к этому базису
-
для
.
Здесь — коэффициент ковариации.
Диагонализация ковариационной матрицы
Все задачи о главных компонентах приводят к задаче диагонализации ковариационной матрицы или выборочной ковариационной матрицы. Эмпирическая или выборочная ковариационная матрица, это
Ковариационная матрица многомерной случайной величины , это
Векторы главных компонент для задач о наилучшей аппроксимации и о поиске ортогональных проекций с наибольшим рассеянием — это ортонормированный набор собственных векторов эмпирической ковариационной матрицы
, расположенных в порядке убывания собственных значений
Эти векторы служат оценкой для собственных векторов ковариационной матрицы
. В базисе из собственных векторов ковариационной матрицы она, естественно, диагональна, и в этом базисе коэффициент ковариации между различными координатами равен нулю.
Если спектр ковариационной матрицы вырожден, то выбирают произвольный ортонормированный базис собственных векторов. Он существует всегда, а собственные числа ковариационной матрицы всегда вещественны и неотрицательны.
Сингулярное разложение матрицы данных
Идея сингулярного разложения
Математическое содержание метода главных компонент — это спектральное разложение ковариационной матрицы , то есть представление пространства данных в виде суммы взаимно ортогональных собственных подпространств
, а самой матрицы
— в виде линейной комбинации ортогональных проекторов на эти подпространства с коэффициентами
. Если
— матрица, составленная из векторов-строк центрированных данных, то
и задача о спектральном разложении ковариационной матрицы
превращается в задачу о сингулярном разложении (англ. Singular value decomposition) матрицы данных
.
Число называется сингулярным числом матрицы
тогда и только тогда, когда существуют правый и левый сингулярные векторы: такие
-мерный вектор-строка
и
-мерный вектор-столбец
(оба единичной длины), что выполнено два равенства:
Пусть — ранг матрицы данных. Сингулярное разложение матрицы данных
— это её представление в виде
где — сингулярное число,
— соответствующий правый сингулярный вектор-столбец, а
— соответствующий левый сингулярный вектор-строка (
). Правые сингулярные векторы-столбцы
, участвующие в этом разложении, являются векторами главных компонент и собственными векторами эмпирической ковариационной матрицы
, отвечающими положительным собственным числам
.
Хотя формально задачи сингулярного разложения матрицы данных и спектрального разложения ковариационной матрицы совпадают, алгоритмы вычисления сингулярного разложения напрямую, без вычисления спектра ковариационной матрицы, более эффективны и устойчивы [1].
Теория сингулярного разложения была создана Дж. Дж. Сильвестром (англ.J. J. Sylvester}}) в 1889 г. и изложена во всех подробных руководствах по теории матриц [1].
Простой итерационный алгоритм сингулярного разложения
Основная процедура — поиск наилучшего приближения произвольной матрицы
матрицей вида
(где
—
-мерный вектор, а
—
-мерный вектор) методом наименьших квадратов:
Решение этой задачи дается последовательными итерациями по явным формулам. При фиксированном векторе значения
, доставляющие минимум форме
, однозначно и явно определяются из равенств
:
Аналогично, при фиксированном векторе определяются значения
:
B качестве начального приближения вектора возьмем случайный вектор единичной длины, вычисляем вектор
, далее для этого вектора
вычисляем вектор
и т. д. Каждый шаг уменьшает значение
. В качестве критерия остановки используется малость относительного уменьшения значения минимизируемого функционала
за шаг итерации (
) или малость самого значения
.
В результате для матрицы получили наилучшее приближение матрицей
вида
(здесь верхним индексом обозначен номер итерации). Далее, из матрицы
вычитаем полученную матрицу
, и для полученной матрицы уклонений
вновь ищем наилучшее приближение
этого же вида и т. д., пока, например, норма
не станет достаточно малой. В результате получили итерационную процедуру разложения матрицы
в виде суммы матриц ранга 1, то есть
. Полагаем
и нормируем векторы
:
В результате получена аппроксимация сингулярных чисел
и сингулярных векторов (правых —
и левых —
).
К достоинствам этого алгоритма относится его исключительная простота и возможность почти без изменений перенести его на данные с пробелами[1], а также взвешенные данные.
Существуют различные модификации базового алгоритма, улучшающие точность и устойчивость. Например, векторы главных компонент при разных
должны быть ортогональны «по построению», однако при большом числе итерации (большая размерность, много компонент) малые отклонения от ортогональности накапливаются и может потребоваться специальная коррекция
на каждом шаге, обеспечивающая его ортогональность ранее найденным главным компонентам.
Для квадратных симметричных положительно определённых матриц описанный алгоритм превращается в метод прямых итераций для поиска собственных векторов (см. статью Собственные векторы, значения и пространства).
Матрица преобразования к главным компонентам
Матрица преобразования данных к главным компонентам строится из векторов главных компонент:
. Здесь
— ортонормированные векторы-столбцы главных компонент, расположенные в порядке убывания собственных значений, верхний индекс
означает транспонирование. Матрица
является ортогональной:
.
После преобразования большая часть вариации данных будет сосредоточена в первых координатах, что даёт возможность отбросить оставшиеся и рассмотреть пространство уменьшенной размерности.
Остаточная дисперсия
Пусть данные центрированы, . При замене векторов данных
на их проекцию на первые
главных компонент
вносится средний квадрат ошибки в расчете на один вектор данных:
где собственные значения эмпирической ковариационной матрицы
, расположенные в порядке убывания, с учетом кратности.
Эта величина называется остаточной дисперсией. Величина
-
называется объяснённой дисперсией. Их сумма равна выборочной дисперсии. Соответствующий квадрат относительной ошибки — это отношение остаточной дисперсии к выборочной дисперсии (то есть доля необъяснённой дисперсии):
По относительной ошибке
оценивается применимость метода главных компонент с проецированием на первые
компонент.
Замечание: в большинстве вычислительных алгоритмов собственные числа
с соответствуюшими собственными векторами — главными компонентами
вычисляются в порядке «от больших
,
(сумму диагональных элементов
Нормировка
Нормировка после приведения к главным компонентам
После проецирования на первые
удобно произвести нормировку на единичную (выборочную) дисперсию по осям. Дисперсия вдоль
й главной компоненты равна
), поэтому для нормировки надо разделить соответствующую координату на
. Это преобразование не является ортогональным и не сохраняет скалярного произведения. Ковариационная матрица проекции данных после нормировки становится единичной, проекции на любые два ортогональных направления становятся независимыми величинами, а любой ортонормированный базис становится базисом главных компонент (напомним, что нормировка меняет отношение ортогональности векторов). Отображение из пространства исходных данных на первые
-
.
Именно это преобразование чаще всего называется преобразованием Кархунена-Лоэва. Здесь
означает транспонирование.
Нормировка до вычисления главных компонент
Предупреждение: не следует путать нормировку, проводимую после преобразования к главным компонентам, с нормировкой и «обезразмериванием» при предобработке данных, проводимой до вычисления главных компонент. Предварительная нормировка нужна для обоснованного выбора метрики, в которой будет вычисляться наилучшая аппроксимация денных, или будут искаться направления наибольшего разброса (что эквивалентно). Например, если данные представляют собой трёхмерные векторы из «метров, литров и килограмм», то при использовании стандартного евклидового расстояния разница в 1 метр по первой координате будет вносить тот же вклад, что разница в 1 литр по второй, или в 1 кг по третьей. Обычно системы единиц, в которых представлены исходные данные, недостаточно точно отображают наши представления о естественных масштабах по осям, и проводится «обезразмеривание»: каждая координата делится на некоторый масштаб, определяемый данными, целями их обработки и процессами измерения и сбора данных.
Есть три cущественно различных стандартных подхода к такой нормировке: на единичную дисперсию по осям (масштабы по осям равны средним квадратичным уклонениям — после этого преобразования ковариационная матрица совпадает с матрицей коэффициентов корреляции), на равную точность измерения (масштаб по оси пропорционален точности измерения данной величины) и на равные требования в задаче (масштаб по оси определяется требуемой точностью прогноза данной величины или допустимым её искажением — уровнем толерантности). На выбор предобработки влияют содержательная постановка задачи, а также условия сбора данных (например, если коллекция данных принципиально не завершена и данные будут ещё поступать, то нерационально выбирать нормировку строго на единичную дисперсию, даже если это соответствует смыслу задачи, поскольку это предполагает перенормировку всех данных после получения новой порции; разумнее выбрать некоторый масштаб, грубо оценивающий стандартное отклонение, и далее его не менять).
Предварительная нормировка на единичную дисперсию по осям разрушается поворотом системы координат, если оси не являются главными компонентами, и нормировка при предобработке данных не заменяет нормировку после приведения к главным компонентам.
Механическая аналогия и метод главных компонент для взвешенных данных
Если сопоставить каждому вектору данных единичную массу, то эмпирическая ковариационная матрица
совпадёт с тензором инерции этой системы точечных масс (делённым на полную массу
), а задача о главных компонентых — с задачей приведения тензора инерции к главным осям. Можно использовать дополнительную свободу в выборе значений масс для учета важности точек данных или надежности их значений (важным данным или данным из более надежных источников приписываются бо́льшие массы). Если вектору данных
придаётся масса
, то вместо эмпирической ковариационной матрицы
Все дальнейшие операции по приведению к главным компонентам производятся так же, как и в основной версии метода: ищем ортонормированный собственный базис
, упорядочиваем его по убыванию собственных значений, оцениваем средневзвешенную ошибку аппроксимации данных первыми
Более общий способ взвешивания даёт максимизация взвешенной суммы попарных расстояний[1] между проекциями. Для каждых двух точек данных,
вводится вес
;
и
. Вместо эмпирической ковариационной матрицы
При
симметричная матрица
положительно определена, поскольку положительна квадратичная форма:
Далее ищем ортонормированный собственный базис
, упорядочиваем его по убыванию собственных значений, оцениваем средневзвешенную ошибку аппроксимации данных первыми
Этот способ применяется при наличии классов: для
Другое применение — снижение влияния больших уклонений (оутлайеров, англ.Outlier), которые могут искажать картину из-за использования среднеквадратичного расстояния: если выбрать
, то влияние больших уклонений будет уменьшено. Таким образом, описанная модификация метода главных компонент является более робастной, чем классическая.
Специальная терминология
В статистике при использовании метода главных компонент используют несколько специальных терминов.
Матрица данных
; каждая строка — вектор предобработанных данных (центрированных и правильно нормированных), число строк —
(количество векторов данных), число столбцов —
(размерность пространства данных);
Матрица нагрузок (Loadings)
; каждый столбец — вектор главных компонент, число строк —
Матрица счетов (Scores)
; каждая строка — проекция вектора данных на
Матрица Z-счетов (Z-scores)
; каждая строка — проекция вектора данных на
Матрица ошибок (или остатков) (Errors or residuals)
.
Основная формула:
Пределы применимости и ограничения эффективности метода
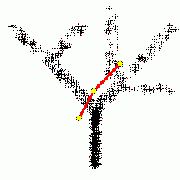 Построение ветвящихся главных компонент методом топологических грамматик. Крестики — точки данных, красное дерево с желтыми узлами — аппроксимирующий дендрит[1].
Построение ветвящихся главных компонент методом топологических грамматик. Крестики — точки данных, красное дерево с желтыми узлами — аппроксимирующий дендрит[1].
Метод главных компонент применим всегда. Распространённое утверждение о том, что он применим только к нормально распределённым данным (или для распределений, близких к нормальным) неверно: в исходной формулировке К. Пирсона ставится задача об аппроксимации конечного множества данных и отсутствует даже гипотеза о их статистическом порождении, не говоря уж о распределении.
Однако метод не всегда эффективно снижает размерность при заданных ограничениях на точность
Примеры использования
Компрессия изображений и видео
Для уменьшения пространственной избыточности пикселей при кодировании изображений и видео используется линейные преобразования блоков пикселей. Последующие квантования полученных коэффициентов и кодирование без потерь позволяют получить значительные коэффициенты сжатия. Использование преобразования PCA в качестве линейного преобразования является для некоторых типов данных оптимальным с точки зрения размера полученных данных при одинаковом искажении [1]. На данный момент этот метод активно не используется, в основном из-за большой вычислительной сложности. Также сжатия данных можно достичь отбрасывая последние коэффициенты преобразования.
Подавление шума на изображениях [1]
Основная суть метода — при удалении шума из блока пикселей представить окрестность этого блока в виде набора точек в многомерном пространстве, применить к нему PCA и оставить только первые компоненты преобразования. При этом предполагается, что в первых компонентах содержится основная полезная информация, оставшиеся же компоненты содержат ненужный шум. Применив обратное преобразование после редукции базиса главных компонент, мы получим изображение без шума.
Индексация видео
Основная идея — представить при помощи PCA каждый кадр видео несколькими значениями, которые в дальнейшем будут использоваться при построении базы данных и запросам к ней. Столь существенная редукция данных позволяет значительно увеличить скорость работы и устойчивость к ряду искажений в видео.
Биоинформатика
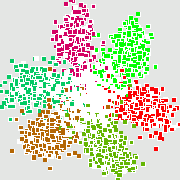 Рис. А. Проекция ДНК-блуждания на первые 2 главные компоненты для генома бактерии Streptomyces coelicolor
Рис. А. Проекция ДНК-блуждания на первые 2 главные компоненты для генома бактерии Streptomyces coelicolor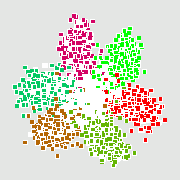 Рис. Б. Проекция ДНК-блуждания на первые 3 главные компоненты для генома бактерии Streptomyces coelicolor. Вращение применяется для визуализации трехмерной конфигурации
Рис. Б. Проекция ДНК-блуждания на первые 3 главные компоненты для генома бактерии Streptomyces coelicolor. Вращение применяется для визуализации трехмерной конфигурацииМетод главных компонент интенсивно используется в биоинформатике для сокращения размерности описания, выделения значимой информации, визуализации данных и др. Один из распространнённых вариантов использования — анализ соответствий (англ. Correspondence Analysis) [1]. На иллюстрациях (Рис. А, Б) генетический текст (см. статью Трансляция (биология)) представлен как множество точек в 64-мерном пространстве частот триплетов. Каждая точка соответствует фрагменту ДНК в скользящем окне длиной 300 нуклеотидов (ДНК-блуждание). Этот фрагмент разбивается на неперекрывающиеся триплеты, начиная с первой позиции. Относительные частоты этих триплетов в фрагменте и составляют 64-мерный вектор. На Рис. А представлена проекция на первые 2 главные компоненты для генома бактерии Streptomyces coelicolor. На Рис. Б представлена проекция на первые 3 главные комроненты. Оттенками красного и коричневого выделены фрагменты кодирующих последовательностей в прямой цепи ДНК, а оттенками зеленого выделены фрагменты кодирующих последовательностей в обратной цепи ДНК. Черным помечены фрагменты, принадлежащие некодирующей части. Анализ методом главных компонент большинства известных бактериальных геномов представлен на специализированном сайте[1].
Хемометрика
Метод главных компонент — один из основных методов в хемометрике (англ. Chemometrics). Позволяет разделить матрицу исходных данных X на две части: «содержательную» и «шум». По наиболее популярному определению [1] «Хемометрика — это химическая дисциплина, применяющая математические, статистические и другие методы, основанные на формальной логике, для построения или отбора оптимальных методов измерения и планов эксперимента, а также для извлечения наиболее важной информации при анализе экспериментальных данных».
Психодиагностика
Психодиагностика является одной из наиболее разработанных областей приложения метода главных компонент [1]. Стратегия использования основывается на гипотезе об автоинформативности экспериментальных данных, которая подразумевает, что диагностическую модель можно создать путем аппроксимации геометрической структуры множества объектов в пространстве исходных признаков. Хорошую линейную диагностическую модель удается построить, когда значительная часть исходных признаков внутренне согласованна. Если эта внутренняя согласованность отражает искомый психологический конструкт, то параметры линейной диагностической модели (веса признаков) дает метод главных компонент.
Общественные науки
Метод главных компонент — один из основных инструментов эконометрики. Он применяется для: (1) наглядного представления данных; (2) обеспечения лаконизма моделей, упрощения счета и интерпретации; (3) сжатия объемов хранимой информации. Метод обеспечивает максимальную информативность и минимальное искажение геометрической структуры исходных данных. В социологии метод небходим для решения первых двух основных задач[1]: (1) анализ данных (описание результатов опросов или других исследований, представленных в виде массивов числовых данных); (2) описание социальных явлений (построение моделей явлений, в том числе и математических моделей). В политологии метод главных компонент был основным инструментом проекта «Политический Атлас Современности»[1] для линейного и нелинейного анализа рейтингов 192 стран мира по пяти специально разработанным интегральным индексам (уровня жизни, международного влияния, угроз, государственности и демократии). Для картографии результатов этого анализа разработана специальная ГИС (Геоинформационная система), объединяющая географическое пространство с пространством признаков.
Сокращение размерности динамических моделей
Проклятие размерности (англ. Curse of dimensionality}}) затрудняет моделирование сложных систем. Сокращение размерности модели — необходимое условие успеха моделирования. Для достижения этой цели создана разветвленная математическая технология. Метод главных компонент также используется в этих задачах (часто под названием истинное или собственное ортогональное разложение — англ. proper orthogonal decomposition (POD)). Например, при описании динамики турбулентности динамические переменные — поле скоростей — принадлежат бесконечномерному пространству (или, если предствлять поле его значениями на достаточно мелкой сетке, — конечномерному пространству большой размерности). Можно набрать большую коллекцию мгновенных значений полей и применить к этому множеству многомерных «векторов данных» метод главных компонент. Эти главные компоненты называются также эмпирические собственные векторы. В некоторых случаях (структурная турбулентность) метод дает впечатляющее сокращение размерности[1] Другие области применения этой техники сокращения динамических моделей чрезвычайно разнообразны — от теоретических основ химической технологии (англ. chemical engineering science}}) до океанологии и климатологии.
Литература
Классические работы
- Pearson K., On lines and planes of closest fit to systems of points in space, Philosophical Magazine, (1901) 2, 559—572; а также на сайте PCA.
- Sylvester J.J., On the reduction of a bilinear quantic of the nth order to the form of a sum of n products by a double orthogonal substitution, Messenger of Mathematics, 19 (1889), 42—46; а также на сайте PCA.
- Frećhet M. Les élements aléatoires de nature quelconque dans un espace distancié. Ann. Inst. H. Poincaré, 10 (1948), 215—310.
Основные руководства (стандарт де-факто)
- Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика. Классификация и снижение размерности.— М.: Финансы и статистика, 1989.— 607 с.
- Jolliffe I.T. Principal Component Analysis, Series: Springer Series in Statistics, 2nd ed., Springer, NY, 2002, XXIX, 487 p. 28 illus. ISBN 978-0-387-95442-4
Сборник современных обзоров
- Gorban A. N., Kegl B., Wunsch D., Zinovyev A. Y. (Eds.), Principal Manifolds for Data Visualisation and Dimension Reduction, Series: Lecture Notes in Computational Science and Engineering 58, Springer, Berlin — Heidelberg — New York, 2007, XXIV, 340 p. 82 illus. ISBN 978-3-540-73749-0 (а также онлайн).
Ссылки
- A tutorial on Principal Components Analysis, Lindsay I Smith, 2002
- Нелинейный метод главных компонент (сайт-библиотека)
Примечания
-



